
티스토리 뷰
Full-Text Search 인덱싱으로 쿼리 성능 개선하기
과거 진행한 프로젝트 리팩토링을 진행하면서 검색 쿼리의 개선을 시도했다.
인덱스를 쓰지 않는 쿼리
개선 대상은 특정 키워드로 게시글을 조회하는 쿼리다. 이 쿼리는 where 절에 like 문과 '%키워드%' 형태로 조건이 걸려 있었다. 이런 방식의 쿼리는 인덱스를 쓰지 않는 풀 테이블 스캔을 해 개선점이 있을 거라 판단했다.

- type 값이 ALL, 즉 풀 테이블 스캔
당연히 개선 방법으로 인덱스 사용이 가장 먼저 떠올랐지만, 한편으론 무수히 많은 문자열 조합이 가능한 TEXT 데이터에 인덱스를 생성하는 것이 가능할까? 하는 의문도 들었다. 어쩔 수 없이 검색 엔진을 도입해야 하나? 생각도 했지만, 간단한 검색 기능일 뿐인데 과하다는 생각도 들고 시간과 비용이 너무 많이 들 것 같아 고민이 됐다.
조금 조사해 보니 이럴 때 사용하는 Full-Text Search 인덱스란게 존재했다.
Full-Text Search Index
텍스트 데이터 특성상 부분 분자열이나 단어 단위의 검색이 필요한데, Full-Text 인덱스는 이를 위해 역인덱스 방식을 사용해 검색 성능을 높인다. 데이터를 단어나 형태소 단위로 분리하고, 이렇게 분리된 단어를 키로 하여 해당 단어가 존재하는 레코드 위치 정보를 값으로 가지는 방식이다.
부하 테스트
먼저, nGrinder를 이용해 테스트를 진행해 봤다.
- DB 데이터 1만 건
- VUser 500명
- 20분간 수행
개선 전
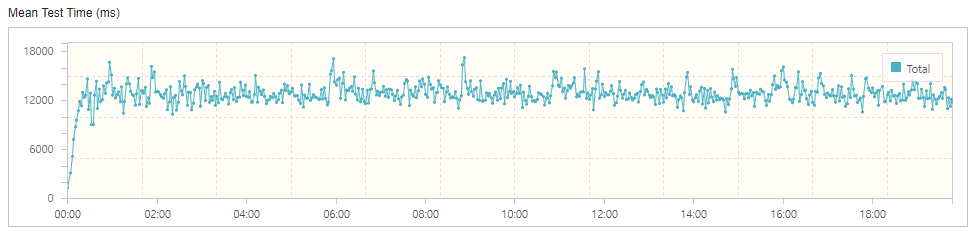
어떤 키워드로 검색하느냐에 따라 차이가 있었지만, 대체로 평균 응답 시간은 12초 정도로 측정됐다. 이제 Full-Text Search 인덱스를 생성해서 쿼리 성능을 개선해 보자.
Full-Text 인덱스 생성 및 사용
-- 생성
create fulltext index 인덱스명 on 테이블명(컬럼1, 컬럼2, ...);-- 사용
select 컬럼1, 컬럼2, ...
from 테이블명
where match(조건 컬럼) against('검색할 키워드');- fulltext search는 match() against() 구문으로 사용

- 쿼리 수행 시, fulltext index 사용하는 것 확인
위와 같이 인덱스를 생성하고 사용하면 끝일 줄 알았는데, 테스트로 쿼리를 수행해 보니 분명 존재하는 데이터인데도 조회되지 않거나 일부만 되는 등 이상한 점이 많았다. 왜 그런지 알아보니 파서에 관한 내용들이 나왔다.
알고 보니...
Full-Text Search 인덱스는 내부적으로 파서가 동작해 만들어진다. 어떤 파서가 동작하느냐에 따라 다른 방식으로 인덱스가 생성되는데, 내가 원하는 요구사항에 맞춰서 파서를 세팅해주지 않아 생기는 문제였다.
앞서 개선하기 전 쿼리는 like '%키워드%' 를 사용했다. 이는 검색어가 텍스트의 어느 위치에 있든지, 완전한 단어인지 아닌지 상관없이 검색어를 포함하는 모든 데이터를 조회하기 위함이었다. 하지만, 위와 같이 인덱스를 생성하면 기본적인 built-in 파서가 동작한다. 이 파서는 공백을 기준으로 데이터를 분리하기 때문에, 하나의 완성된 단어나 어절 단위로 인덱싱 된다. 이 때문에 완성된 단어가 아니면 내가 원하는 결과가 나오지 않았던 것이다. 인덱스 때문에 성능이 개선되었을지는 몰라도 기존 요구사항과는 달라졌기에 올바르게 개선되었다고 볼 수는 없었다.
요구사항에 맞는 검색 기능을 위해서는 다른 방식의 파서를 사용해야 한다. 완성된 단어가 아닌 지정된 크기의 토큰으로 인덱싱하는 n-gram 파서를 이용해 볼 수 있겠다.
파서에 따라 다른 인덱스 구현 방식
앞서 언급한 대로 mysql은 full-text 인덱스를 생성할 때 사용되는 파서를 여러 가지 제공하는데, 파서에 따라 인덱싱 되는 데이터나 그 개수가 달라진다. built-in 파서와 n-gram 파서를 비교해 보자.
built-in
- 기본적으로 MySQL에 내장되어 있음
- 공백을 구분자로 사용하여 텍스트를 단어 단위로 분리해 인덱싱
- ex) "나는 인환" => "나는", "인환"
n-gram
- 연속된 n개의 문자 또는 단어를 의미, 2-gram은 두 개의 연속된 문자 또는 단어를 나타냄
- 텍스트를 n-gram 토큰으로 분리하여 인덱싱
- ex) n = 2 일 때 "나는 인환" => "나는", "는 ", " 인", "인환"
따라서 n-gram은 일부 단어가 일치하는 경우에도 검색 결과를 반환하여 부분 문자열 검색에 유용하고, built-in은 단어 단위의 검색에 적합하다.
n-gram 파서로 fulltext 인덱스 생성
-- 생성
create fulltext index 인덱스명 on 테이블명(컬럼1, 컬럼2, ...) with parser ngram;n-gram 파서로 인덱스를 생성하는 방법은 기존 fulltext 인덱스 생성 쿼리에서 'with parser ngram'를 붙이면 된다. 이렇게 새로운 인덱스를 생성한 뒤 부하 테스트를 진행했다.
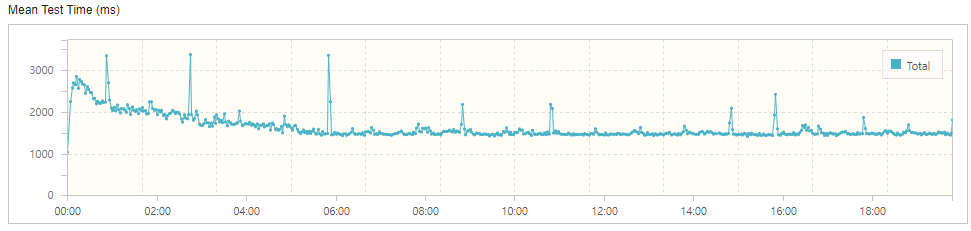
평균 응답 시간 1.595초로 약 8배 정도 향상된 수치를 보였다.
처음엔 단순히 인덱스로 개선 한번 해볼까? 정도의 시도였는데 하다 보니 생각보다 예상치 못한 문제를 경험하게 돼 깊은 공부가 된 것 같다.
'프로그래밍' 카테고리의 다른 글
| 굳이, 팩토리 클래스 적용하기 (0) | 2025.01.15 |
|---|---|
| 정적 멤버 클래스로 DTO 관리하기 (0) | 2023.05.14 |
| ArrayList에 요소가 추가되는 과정 파헤쳐보기 (0) | 2023.02.03 |
| 이펙티브자바 - 인터페이스는 구현하는 쪽을 생각해 설계하라 (0) | 2023.01.31 |
| 클래스와 멤버의 접근 권한을 최소화하라 (0) | 2022.12.23 |